이전에는 모델이 특성에 따라 해석되었습니다. 이번에는 하나의 사례에 대한 정보만 포함된 행(분석 단위, 데이터 포인트)을 기반으로 합니다.
1. 개별 조건부 기대(ICE) 도표
특정 분석 단위에서 하나의 특정 특성이 변경되면 예측 값이 어떻게 변경됩니까? 그 양상을 확인하는 것이 ICE 플롯이다.
예를 들어 나이, 학력, 국가, 직업 등에 대한 특성이 있고, 연봉을 기록하는 대상이 있다. 이때 나이가 줄거나 늘어남에 따라 연봉의 예측값이 달라지게 됩니다.
# 확인하고자 하는 분석단위 가져오기
one_datapoint = X_val_encoded.iloc((3)).copy()
# age 변화 범위 정하기
age_test_range = range(X_val_encoded("age").min(), X_val_encoded("age").max() + 1)
# for문으로
results = ()
for age in age_test_range:
one_datapoint("age") = age # age값 바꾸기
one_datapoint_pred_proba = boosting.predict(one_datapoint)(:, 1)
# 바뀐 age 데이터를 통한 예측
results.append(one_datapoint_pred_proba.item())
results = np.array(results)
results -= results(0)
# 나이가 최소일 때의 예측값을 기준으로 하고 그 변화값을 관찰한다
# 시각화
import matplotlib.pyplot as plt
plt.plot(age_test_range, results)
plt.xlabel("age")
plt.ylabel("$\Delta$ pred_proba")
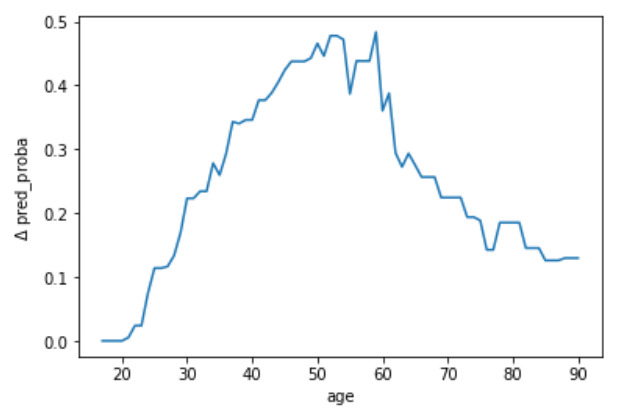
위의 이미지에 따르면 연령은 60세까지 꾸준히 증가했다가 감소할 것으로 분석단은 예측하고 있습니다.
2. 부분의존도(PDP)
PDP는 모든 분석 단위에 ICE 플롯을 적용한 후의 평균입니다. 모델이 해당 특성을 분석하고 이해하는 방법을 결정할 수 있습니다.
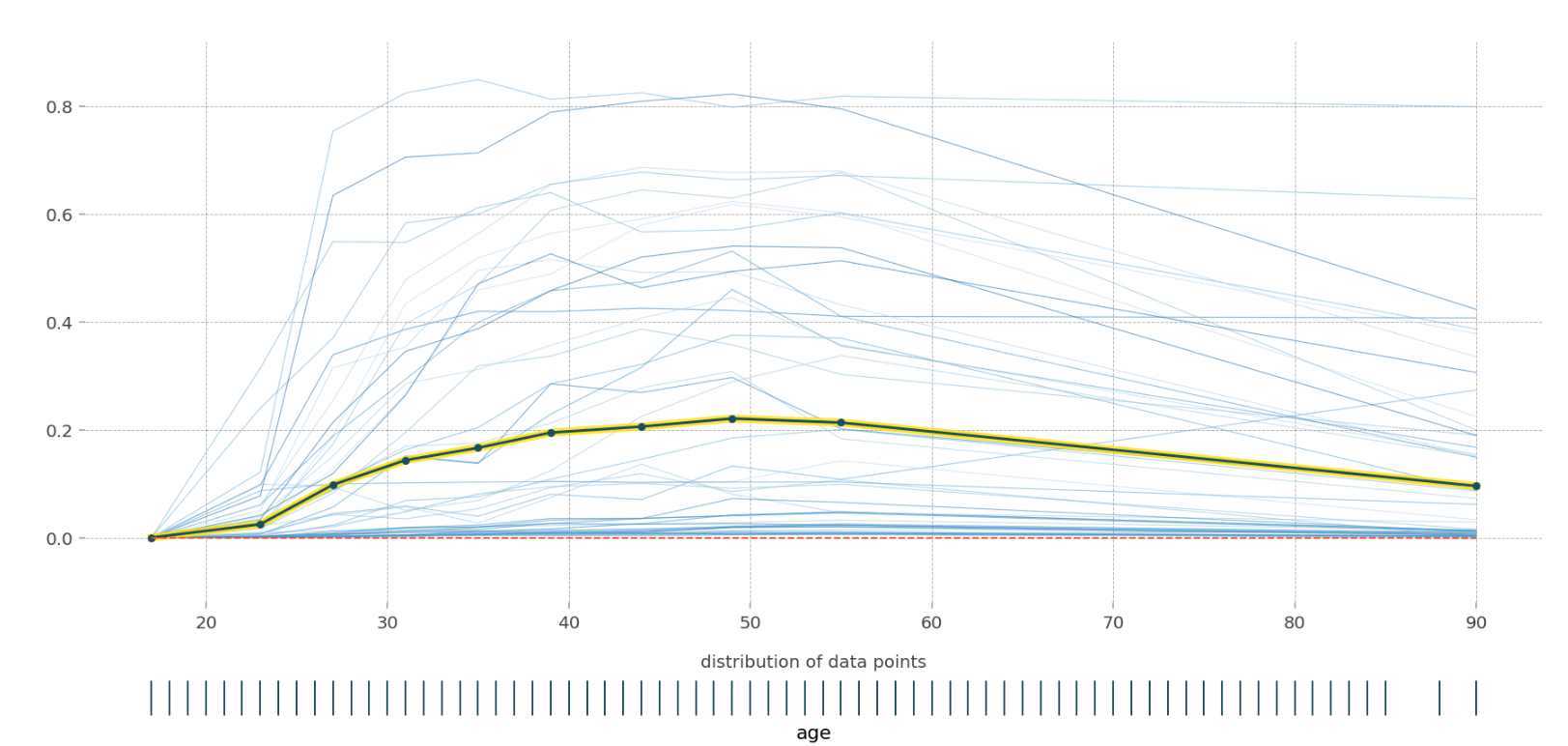
이때 평균선뿐만 아니라 개별선도 표시하여 특별한 경우 예측값의 변화를 살펴보았다. 아래와 같이 두 가지 특성을 히트맵으로 함께 볼 수도 있습니다.

*클라이언트는 현장에서 AI 개발자에게 어떤 질문을 하고 있나요?
① 모델이 그렇게 예측한 이유는 무엇입니까? –-> 기능 중요도, ICE, PDP 등을 사용하여 설명할 수 있어야 합니다.
② 모델이 비즈니스 문제를 해결할 수 있습니까? –> 모델이 가져올 수익을 살펴봐야 합니다.
*encoder.mapping 코드를 입력하면 각 카테고리가 어떤 번호로 분류되는지 알 수 있습니다.